



The conversation around AI infrastructure often focuses on access. More GPUs, more capacity, and more compute are commonly viewed as the path to greater AI competitiveness. Yet for enterprises deploying production systems, hardware availability is only one part of the equation. Reliability, networking, compliance, support, and operational tooling often determine whether an infrastructure platform can move beyond experimentation and become a long-term foundation for AI workloads.
Decentralized Compute Is Growing, But Enterprise Requirements Remain Different
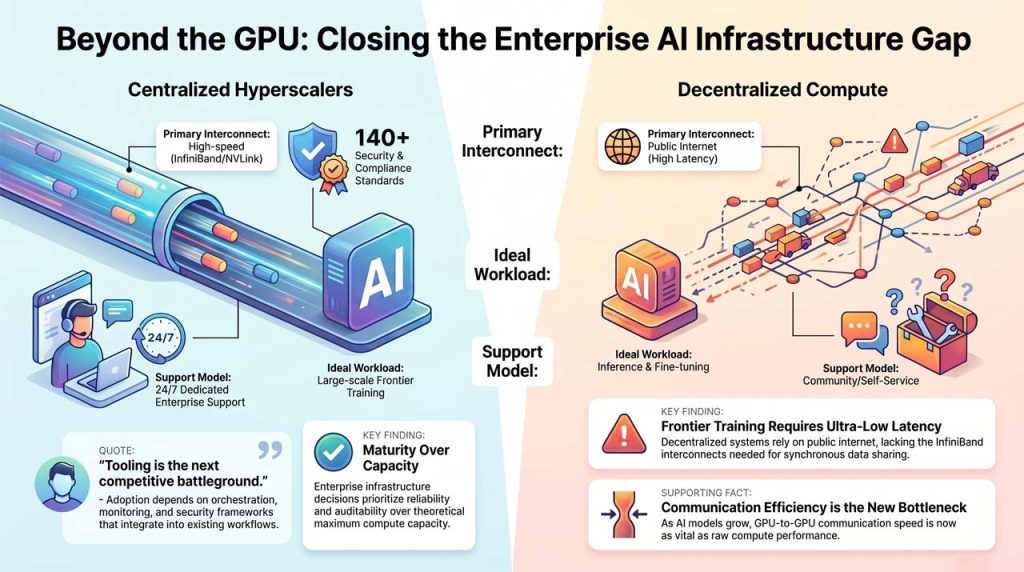
Decentralized compute platforms have attracted increasing attention as organizations search for alternatives to traditional cloud infrastructure. By tapping distributed compute resources, these models promise greater flexibility and potentially lower costs for certain AI workloads.
However, the requirements for enterprise AI infrastructure extend well beyond access to available GPUs.
As discussion around decentralized AI infrastructure continues with KoreaTechDesk, Greg Osuri, founder of Akash Network and CEO of Overclock Labs, has emerged as one of the more prominent voices in the space. Through his work building decentralized cloud infrastructure and advocating for alternative compute models, he argues that decentralized infrastructure has made meaningful progress but still faces limitations when compared with large cloud providers.
“Training efficiency remains substantially stronger on large, centralized hyperscalers.”
His observation highlights an important distinction that is often overlooked in infrastructure discussions. AI deployment involves different categories of workloads, and not all of them place the same demands on infrastructure architecture.

Why Frontier AI Training Still Favors Centralized Infrastructure
Many decentralized platforms perform well for inference, fine-tuning, and other workloads that can be distributed across separate compute resources. Large-scale model training presents a different challenge.
According to Osuri, decentralized systems are still struggling with frontier AI training because of networking constraints.
“Decentralized models struggle with large-scale frontier AI training because they rely on the public internet, which lacks the ultra-low-latency physical interconnects (like InfiniBand) required for synchronous data sharing.”
This limitation reflects how modern AI training systems are designed. Large language models often require thousands of GPUs to continuously exchange information during training. Infrastructure providers such as Amazon Web Services, Microsoft Azure, and Google Cloud have spent years building tightly integrated environments that combine specialized networking, storage systems, and clustered GPU resources.
NVIDIA’s AI infrastructure architecture similarly emphasizes technologies such as InfiniBand, NVLink, and high-bandwidth GPU communication frameworks designed to minimize synchronization delays during large-scale training.
And as model sizes continue increasing, communication efficiency can become almost as important as compute performance itself.

Enterprise Buyers Need More Than Compute Capacity
Furthermore, the gap between infrastructure experimentation and enterprise deployment is not purely technical. Organizations evaluating infrastructure platforms must also consider support models, contractual arrangements, procurement processes, and operational accountability.
Osuri acknowledged that centralized providers still maintain advantages in these areas.
“Decentralized compute does not yet offer the same level of services that a hyperscaler can.”
He added:
“Dedicated enterprise support and bespoke private deals are areas where centralized providers still have an edge.”
This remains particularly relevant for large corporations, regulated industries, and public-sector organizations.
Major cloud providers have spent years building enterprise support and compliance ecosystems around their infrastructure offerings. AWS Enterprise Support, for example, provides 24/7 technical assistance and response times as fast as 15 minutes for business-critical incidents, alongside dedicated Technical Account Manager guidance. Google Cloud and Microsoft Azure offer similar enterprise support structures designed to help customers manage production workloads, security requirements, and operational risks.
Beyond support, hyperscalers also maintain extensive compliance portfolios covering standards and regulations that many large organizations require before deploying critical workloads. AWS states that its cloud services support more than 140 security standards and compliance certifications globally.
So, for regulated industries such as finance, healthcare, and government, these operational and compliance capabilities often carry as much weight as raw computing performance when infrastructure decisions are made.
Tooling and Operational Maturity May Become the Next Competitive Battleground
Moreover, infrastructure adoption is increasingly influenced by software ecosystems rather than hardware alone.
As AI deployments become more complex, organizations require orchestration systems, monitoring tools, security frameworks, workload management capabilities, and operational visibility across environments.
That is why Osuri believes tooling remains a critical area for decentralized infrastructure to develop further.
“I believe ecosystem tooling will also be critical for adoption for enterprises.”
The challenge is becoming more important as enterprises scale AI deployments across multiple teams and business units. Infrastructure must integrate into existing workflows while maintaining reliability, security, and governance requirements.
For many organizations, infrastructure maturity is measured less by theoretical capability and more by how easily teams can deploy, manage, audit, and troubleshoot production workloads.

Why This Matters for South Korea’s AI Infrastructure Expansion
The discussion carries particular relevance for South Korea.
The country is investing heavily in AI infrastructure through national GPU acquisition programs, public-private computing initiatives, and the National AI Computing Center project. According to government announcements, the objective extends beyond expanding compute supply and includes improving access for startups, researchers, and enterprises.
At the same time, Korean cloud providers and technology companies are strengthening their own AI infrastructure offerings. Recent initiatives by companies including Naver Cloud and Kakao Enterprise have increasingly emphasized integrated AI environments that combine GPU resources with networking, cooling, security, monitoring, and enterprise support capabilities.
This reflects a broader industry reality.
AI infrastructure competitiveness is no longer determined solely by how many GPUs are installed. It is increasingly shaped by how effectively those resources can be operated, managed, secured, and integrated into real business environments.
Startups should pay attention to this distinction because infrastructure decisions affect speed, reliability, and scaling costs. Meanwhile, policymakers now face questions about how national AI investments translate into practical deployment capabilities. And infrastructure providers can see how operational maturity is becoming increasingly important alongside hardware expansion.

The Next Phase of AI Infrastructure Competition
In the end, the debate surrounding AI infrastructure is often framed as a contest between centralized and decentralized models.
In practice, the future may be less about replacement and more about suitability.
Different workloads have different requirements. Some can benefit from distributed infrastructure and flexible capacity. Others still depend on tightly coupled systems, specialized networking, enterprise support structures, and mature operational ecosystems.
And as organizations move from experimentation into production deployment, infrastructure decisions become less about accessing compute and more about managing complexity.
The platforms that succeed in the next phase of AI adoption may not simply be those with the largest hardware inventories. They may be the ones that can combine compute, networking, tooling, support, and operational reliability into systems that enterprises trust to run at scale.
Key Takeaway
- Decentralized compute infrastructure continues to expand, but enterprise adoption depends on more than GPU availability.
- Large-scale AI training still favors centralized hyperscalers because of networking technologies such as InfiniBand and tightly integrated GPU clusters.
- Greg Osuri, founder of Akash Network and CEO of Overclock Labs, acknowledges that enterprise support remains an advantage for hyperscaler cloud providers.
- Operational tooling, monitoring, orchestration, and governance capabilities are becoming major factors in infrastructure adoption decisions.
- South Korea’s AI infrastructure strategy increasingly highlights the importance of deployment readiness, not only hardware acquisition.
- The next phase of AI infrastructure competition may be determined by operational maturity rather than compute capacity alone.
– Stay Ahead in Korea’s Startup Scene –
Get real-time insights, funding updates, and policy shifts shaping Korea’s innovation ecosystem.
➡️ Follow KoreaTechDesk on LinkedIn, X (Twitter), Threads, Bluesky, Telegram, Facebook, and WhatsApp Channel.
🤝 Looking to connect with verified Korean companies building globally?
Explore curated company profiles and request direct introductions through beSUCCESS Connect.




